1월 31일 2.42.0 버전이 릴리즈 되었다. 해당 버전을 기준으로 공식문서를 참고해서 읽어보자.
프로메테우스는 오픈 소스의 모니터링, 알람 툴킷 시스템이다.
*알람 툴킷이 뭐지?
알람 툴킷(Alarm Toolkit)은 소프트웨어 개발자가 알람 및 예약된 작업을 구현할 수 있는 라이브러리나 도구 모음입니다. 이를 사용하면 개발자는 알람 및 예약된 작업에 대한 로직을 작성하지 않고도 프로그램에서 쉽게 이러한 작업을 구현할 수 있습니다.
알람 툴킷은 다양한 운영 체제 및 프로그래밍 언어에서 사용할 수 있으며, 예약된 작업을 처리하는 방법과 알람을 설정하고 관리하는 방법을 추상화하여 개발자가 구현을 간소화합니다.
예를 들어, 개발자가 지정한 시간에 작업을 실행하거나 일정 시간이 경과한 후에 알림을 표시하는 등의 작업을 처리하는 데 사용할 수 있습니다.
프로메테우스는 메트릭을 time series data로 저장한다. 즉 메트릭 정보를 저장할 때 정보를 수집한 시간을 같이 저장하며 key-value 쌍의 라벨도 함께 저장할 수 있다.
Architecture
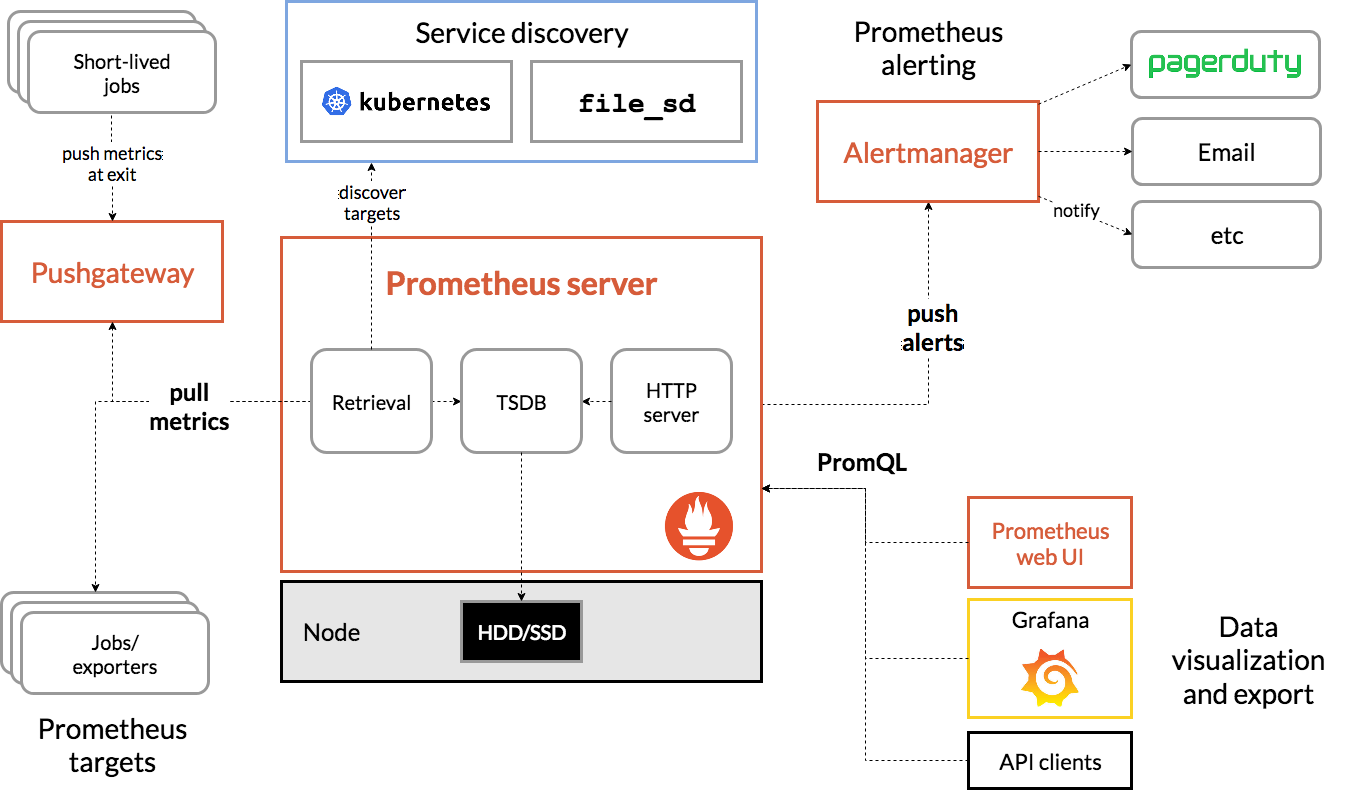
프로메테우스의 에코시스템 컴포넌트를 나타낸 다이어그램이다.
프로메테우스는 jobs 단위로 메트릭을 수집한다. 이때 애플리케이션 서버에 위치하여 가져오는 것이 아니라 pull 방식으로 메트릭을 수집한다.
스크랩한 데이터는 로컬 SSD/HDD에 저장하며 설정해 둔 rule들을 실행하여 데이터를 집계하거나 새로운 time series로 기록하거나 알림을 생성한다.
이때 Grafana를 사용하면 수집한 데이터를 시각화할 수 있다.
프로메테우스를 설치하여 사용하게 될 때 필요하다면 특정 컴포넌트를 추가하여 여러 가지 기능을 적용할 수 있다.
예를 들면 short-lived job을 지원하는 push gateway, HAProxy와 같은 exporters가 있고 alerts을 위한 alertmanager와 이외 다양한 지원 도구들이 있다고 한다.
HAProxy와 같은 로드밸런서의 기술을 지원한다는 게 어디까지 지원되는지도 궁금하긴 하다.
이제 다운로드를 받아서 실행해 보자.
LTS 버전인 2022-12-09에 출시한 2.37.5 버전을 다운로드한다.

압축을 푼 폴더 아래 prometheus.yml이라는 설정파일이 있다.
프로메테우스는 yaml 파일로 설정을 진행한다고 한다. 한번 확인해 보자.
주석으로 상세하게 사용법을 알려준다.

우선 실행시켜 보자
./prometheus --config.file=prometheus.yml아무런 변경하지 않으면 프로메테우스가 자신의 메트릭 엔드포인트에서 자신에 대한 데이터를 수집한다.
프로메테우스 Storage에 대해서도 알아보아야 한다.
프로메테우스는 로컬 디스크를 기반으로 time series database를 가지고 있다. 원한다면 원격 스토리지 시스템과 통합하는 것도 가능하다고 한다.
프로메테우스가 수집한 샘플은 2시간 단위의 블록으로 그룹 지어진다.
각 블록은 chunks 디렉터리, 메타데이터 파일, 인덱스 파일이 담긴 디렉터리로 구성된다.
현재 샘플을 수집 중인 블록은 메모리에 유지하며, 완전한 저장상태로 보기 어렵다.
로컬 스토리지를 이용할 때는 클러스터링이나 복제가 불가능하다는 제약이 있다.
따라서 드라이브나 노드가 중단되면 자체적으로 확장하거나 내구성을 보장할 수 없다.
스토리지 가용성을 위해서는 RAID를 사용하고, 스냅숏을 통해 백업해두어야 한다.
스냅숏은 TSDB의 데이터 디렉터리 및에 있는 snapshots/<datetime>-<rand>에 현재 모든 데이터들의 스냅숏을 생성하며, 이 디렉터리를 응답으로 반환한다.
아니라면 remote read/write API를 통해 외부 저장소를 사용할 수 있다.
프로메테우스는 데이터를 저장할 때 샘플당 평균 1-2바이트 만을 사용한다. 따라서 프로메테우스 서버의 용량을 계획할 땐 다음의 공식을 대략적으로 활용하면 된다고 한다.
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample필요한 디스크 공간은 데이터를 유지해야 하는 초 * 초당 처리되는 샘플의 수 * 샘플의 바이트를 곱하면 필요한 디스크 공간이 도출된다.
저장 공간을 고려해 샘플의 수집 속도를 늦추려면 스크랩하는 시계열 수를 줄이거나, 스크랩 간격을 늘리면 된다. 하지만 같은 시계열에 있는 샘플은 압축할 수 있기 때문에 시계열 수를 줄이는 게 더 효과가 좋다.
VISUALIZATION
그라파나는 프로메테우스 데이터 질의를 지원하기 때문에 다음과 같이 구성할 수 있다.
Spring boot actuactor → prometheus (수집)
grafana → prometheus (시각화)
리눅스에서 grafana를 설치하려면 다음 명령어를 실행하면 된다.
wget <https://dl.grafana.com/enterprise/release/grafana-enterprise-9.3.6-1.x86_64.rpm>
sudo yum install grafana-enterprise-9.3.6-1.x86_64.rpm
실제 별도의 서버에 grafana, prometheus를 설치하여 진행하는 것이 좋아 보인다.
다만 대부분의 예시나 블로그, 기술블로그를 참고하면 설명하기 위해 로컬에 설치하여 동일 네트워
크 통신을 하는 것으로 보인다.
Grafana를 받고 실행하면 3000번 포트를 default로 실행된다.
로그인을 진행하는데 admin/admin으로 로그인한 후 비밀번호를 변경하면 된다.
SpringBoot APM Dashboard | Grafana Labs
SpringBoot APM Dashboard | Grafana Labs
Edit Delete Confirm Cancel
grafana.com
테스트를 위해 대시보드 JSON 파일을 다운로드한다.
이후 대시보드를 확인하면 다음과 같은 화면이 나온다.

해당 JSON 파일에는 꽤 괜찮은 데이터를 시각화해 준다.
하지만 커스텀을 하여 내가 원하는 panel을 추가해야 할 것 같다. 그리고 보이는 모든 지표가 무엇인지 잘 모른다.
생각해 보자 Grafana는 프로메테우스의 쿼리를 지원한다.
커스텀을 위해선 내 목표에 필요한 데이터를 어떻게 질의하는지 알아야 한다.
PromQL 가이드가 존재한다. 이를 한번 보고 가장 한눈에 볼 수 있도록 여러 커스텀 위젯을 만들어보아야 할 것 같다.
다음에는 커스텀 위젯을 만들어 봐야겠다.
Querying basics | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
Download Grafana | Grafana Labs
Download Grafana | Grafana Labs
Overview of how to download and install different versions of Grafana on different operating systems.
grafana.com
Overview | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
'BackEnd' 카테고리의 다른 글
| 🛠️ Swagger ? (0) | 2023.07.12 |
|---|---|
| SSH 접속 불가 (0) | 2023.03.15 |
| Monitoring (0) | 2023.02.16 |
| CQRS Pattern (0) | 2023.02.02 |
| Event (0) | 2023.01.30 |




댓글